
I am currently a Ph.D. Student in the Department of Computer Science and Engineering at Sogang University, supervised by Prof. Junsuk Choe. Prior to this, I obtained my M.S. Degree in the Department of Artificial Intelligence at Sogang University advised by the same supervisor. Previously, I received a B.S. Degree at the same university.
Research Interests: I research how to make vision-language models (VLMs) more scalable. In particular, my work focuses on continually training VLMs on new datasets and unlearning existing knowledge from VLMs without training them from scratch. I also explore how to scale VLMs using imperfect datasets, such as self-supervised, semi-supervised, weakly supervised, and few-shot learning datasets.
My recent primary research question is to analyze how the scalability of VLMs affects vision-language-action models (VLAs).
News
Publications (* equal contribution, † co-corresponding author)
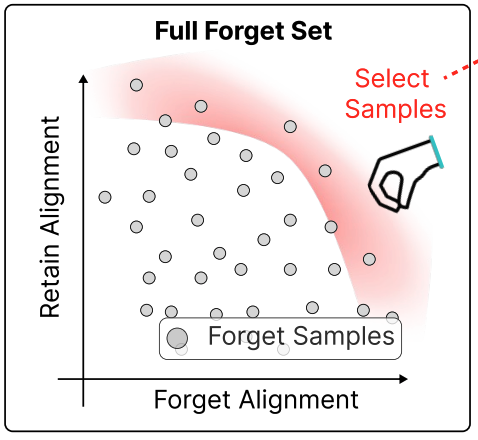
Alignment-aware Data Selection for Unlearning in Contrastive Vision-Language Models
Dongjun Hwang, Yejin Kim, Beomyun Kwon, Junsuk Choe
ICML Workshop on MemFM 2026
We observe that unlearning performance in contrastive VLMs largely depends on the composition of the forget set, and propose ALISE—a data selection framework that measures each sample's alignment with both the retain set and the full forget set to facilitate targeted knowledge removal while preserving model utility.
Alignment-aware Data Selection for Unlearning in Contrastive Vision-Language Models
Dongjun Hwang, Yejin Kim, Beomyun Kwon, Junsuk Choe
ICML Workshop on MemFM 2026
We observe that unlearning performance in contrastive VLMs largely depends on the composition of the forget set, and propose ALISE—a data selection framework that measures each sample's alignment with both the retain set and the full forget set to facilitate targeted knowledge removal while preserving model utility.
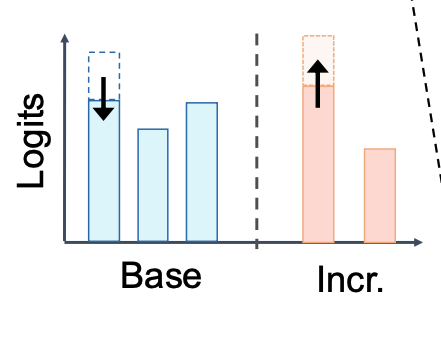
Training-Free Uncertainty-guided Logit Adjustment for Few-Shot Class-Incremental Learning
Sungwon Woo, Dongjun Hwang, Shiwon Kim, Junsuk Choe, Jongho Nang
CVPR Findings 2026
We propose a training-free approach that leverages uncertainty estimates to adaptively adjust logits in few-shot class-incremental learning, effectively preventing catastrophic forgetting without requiring any retraining or modification of the model.
Training-Free Uncertainty-guided Logit Adjustment for Few-Shot Class-Incremental Learning
Sungwon Woo, Dongjun Hwang, Shiwon Kim, Junsuk Choe, Jongho Nang
CVPR Findings 2026
We propose a training-free approach that leverages uncertainty estimates to adaptively adjust logits in few-shot class-incremental learning, effectively preventing catastrophic forgetting without requiring any retraining or modification of the model.
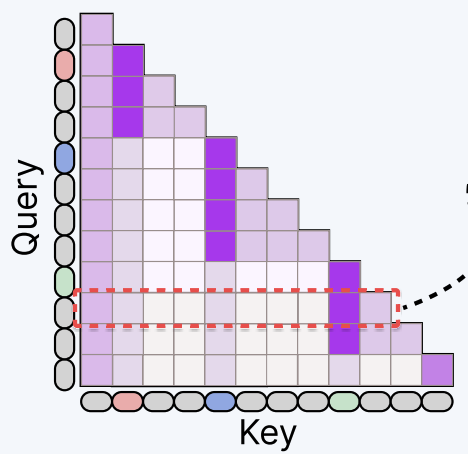
Enhancing Multi-Image Understanding through Delimiter Token Scaling
Minyoung Lee, Yeji Park, Dongjun Hwang, Yejin Kim, Seong Joon Oh, Junsuk Choe
ICLR 2026
We identify cross-image information leakage as a key bottleneck in Large Vision-Language Models (LVLMs) and propose scaling hidden states of delimiter tokens to reinforce intra-image interaction while suppressing undesired cross-image interference, achieving consistent gains on multi-image benchmarks with no additional training or inference cost.
Enhancing Multi-Image Understanding through Delimiter Token Scaling
Minyoung Lee, Yeji Park, Dongjun Hwang, Yejin Kim, Seong Joon Oh, Junsuk Choe
ICLR 2026
We identify cross-image information leakage as a key bottleneck in Large Vision-Language Models (LVLMs) and propose scaling hidden states of delimiter tokens to reinforce intra-image interaction while suppressing undesired cross-image interference, achieving consistent gains on multi-image benchmarks with no additional training or inference cost.
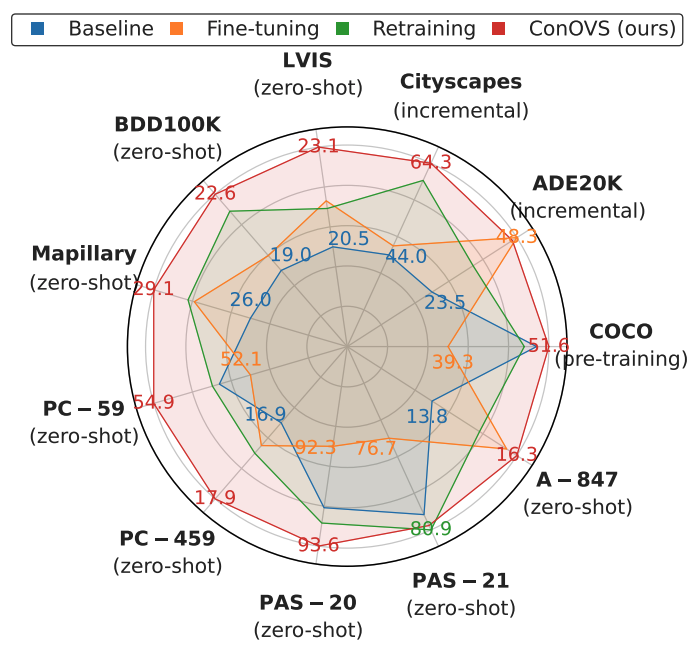
OVS Meets Continual Learning: Towards Sustainable Open-Vocabulary Segmentation
Dongjun Hwang, Yejin Kim, Minyoung Lee, Seong Joon Oh, Junsuk Choe
NeurIPS 2025
We address the overlooked problem of continual learning in open-vocabulary segmentation, and propose ConOVS—a Mixture-of-Experts framework that dynamically routes each input to incremental expert decoders, enabling models to recognize new categories without forgetting previously learned ones.
OVS Meets Continual Learning: Towards Sustainable Open-Vocabulary Segmentation
Dongjun Hwang, Yejin Kim, Minyoung Lee, Seong Joon Oh, Junsuk Choe
NeurIPS 2025
We address the overlooked problem of continual learning in open-vocabulary segmentation, and propose ConOVS—a Mixture-of-Experts framework that dynamically routes each input to incremental expert decoders, enabling models to recognize new categories without forgetting previously learned ones.
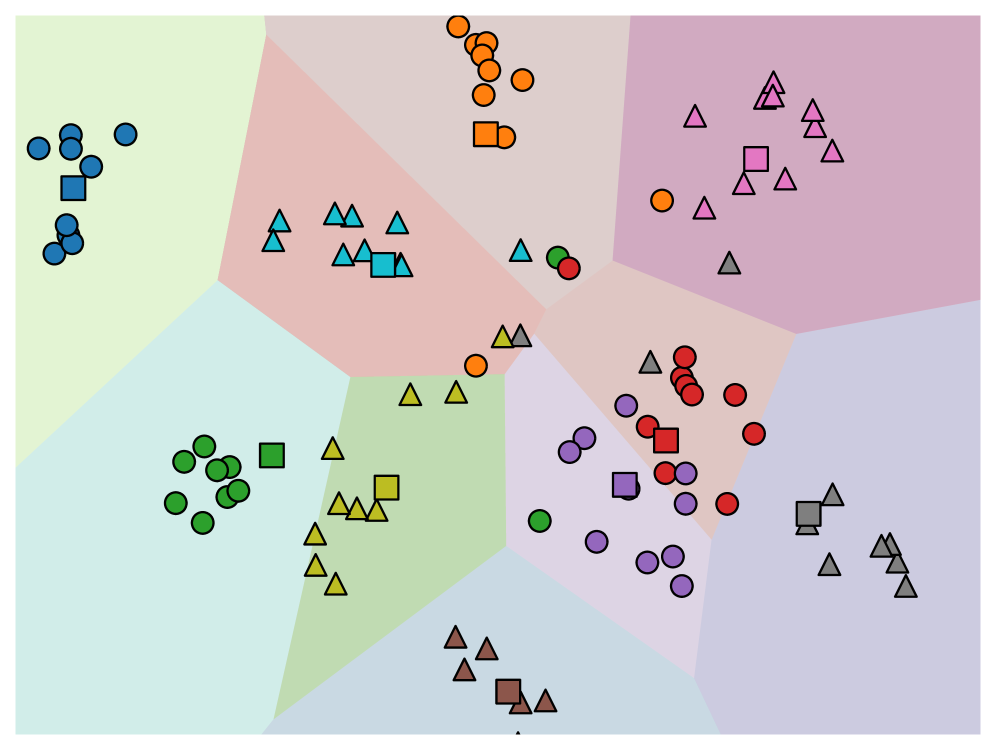
Does Prior Data Matter? Exploring Joint Training in the Context of Few-Shot Class-Incremental Learning
Shiwon Kim*, Dongjun Hwang*†, Sungwon Woo*, Rita Singh†
ICCV Workshop on Continual Learning in Computer Vision 2025
We investigate when and how prior data should be utilized in few-shot class-incremental learning, revealing that naive joint training fails under severe class imbalance, and propose an imbalance-aware joint training benchmark to guide practitioners on optimal training strategies.
Does Prior Data Matter? Exploring Joint Training in the Context of Few-Shot Class-Incremental Learning
Shiwon Kim*, Dongjun Hwang*†, Sungwon Woo*, Rita Singh†
ICCV Workshop on Continual Learning in Computer Vision 2025
We investigate when and how prior data should be utilized in few-shot class-incremental learning, revealing that naive joint training fails under severe class imbalance, and propose an imbalance-aware joint training benchmark to guide practitioners on optimal training strategies.

Small Object Matters in Weakly Supervised Object Localization
Dongjun Hwang, Seong Joon Oh, Junsuk Choe
Neurocomputing 2025 SJR Q1; IF: 5.50
We reveal that existing WSOL methods systematically fail to localize small objects, and address this gap by introducing new evaluation metrics and a contrastive learning framework that zooms in on small regions, significantly improving small-object localization without sacrificing accuracy on larger objects.
Small Object Matters in Weakly Supervised Object Localization
Dongjun Hwang, Seong Joon Oh, Junsuk Choe
Neurocomputing 2025 SJR Q1; IF: 5.50
We reveal that existing WSOL methods systematically fail to localize small objects, and address this gap by introducing new evaluation metrics and a contrastive learning framework that zooms in on small regions, significantly improving small-object localization without sacrificing accuracy on larger objects.
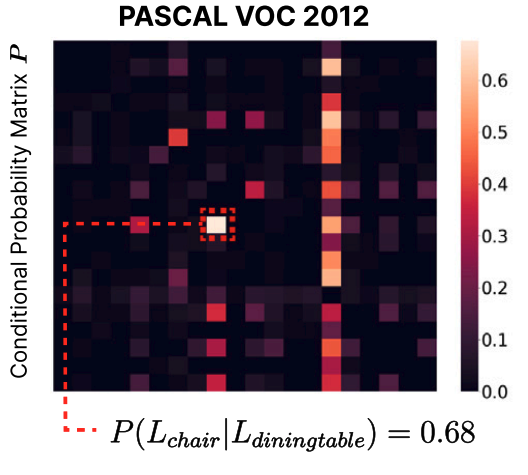
Curriculum Learning with Class-label Composition for Weakly Supervised Semantic Segmentation
Dongjun Hwang, Hyoseo Kim, Doyeol Baek, Hyunbin Kim, Inhye Kye, Junsuk Choe
Pattern Recognition Letters 2025 SJR Q1; IF: 3.90
We propose a curriculum learning strategy for weakly supervised semantic segmentation that progressively trains on increasingly complex class-label compositions, effectively alleviating spurious correlations from co-occurring classes and class imbalance across eight WSSS methods on three benchmarks.
Curriculum Learning with Class-label Composition for Weakly Supervised Semantic Segmentation
Dongjun Hwang, Hyoseo Kim, Doyeol Baek, Hyunbin Kim, Inhye Kye, Junsuk Choe
Pattern Recognition Letters 2025 SJR Q1; IF: 3.90
We propose a curriculum learning strategy for weakly supervised semantic segmentation that progressively trains on increasingly complex class-label compositions, effectively alleviating spurious correlations from co-occurring classes and class imbalance across eight WSSS methods on three benchmarks.

Entropy Regularization for Weakly Supervised Object Localization
Dongjun Hwang, Jung-Woo Ha, Hyunjung Shim, Junsuk Choe
Pattern Recognition Letters 2023 SJR Q1; IF: 4.75
We propose a simple entropy regularization term that bridges the gap between classification and localization objectives in WSOL—requiring only one line of code and no architecture changes—consistently improving localization performance across five datasets and multiple backbone networks.
Entropy Regularization for Weakly Supervised Object Localization
Dongjun Hwang, Jung-Woo Ha, Hyunjung Shim, Junsuk Choe
Pattern Recognition Letters 2023 SJR Q1; IF: 4.75
We propose a simple entropy regularization term that bridges the gap between classification and localization objectives in WSOL—requiring only one line of code and no architecture changes—consistently improving localization performance across five datasets and multiple backbone networks.
Education
-
 Sogang UniversityDepartment of Computer Science and Engineering
Sogang UniversityDepartment of Computer Science and Engineering
Ph.D. StudentMar. 2024 – Present -
Sogang UniversityDepartment of Artificial Intelligence
M.S.Mar. 2022 – Feb. 2024 -
Sogang UniversityDepartment of Computer Science and Engineering
B.S.Mar. 2018 – Feb. 2022
Experience
-
 Tübingen AI CenterVisiting Researcher
Tübingen AI CenterVisiting Researcher
Host: Prof. Seong Joon OhMay. 2025 – July. 2025 -
 Carnegie Mellon UniversityVisiting Student
Carnegie Mellon UniversityVisiting Student
IITP AI Intensive Education ProgramAug. 2024 – Feb. 2025
Honors & Awards
-
Smilegate AI Major (DHE) Scholarship2022
-
34th IPIU Workshop, Bronze Award2022